Vitor Meriat
Machine Learning EngineerNLP Under the Hood: A computational historical approach
Sumário
- 1. Introdução
- 2. Conceitos Básicos
- 3. Linguagem Natural e sua Complexidade
- 4. Natural Language Processing
- 5. A historical Review
- 6. Conlusão
- 7. Referências
"Minha pátria é minha língua." Fernando Pessoa
1. Introdução
O método científico supõe que a observação dos fatos seja anterior ao estabelecimento de uma hipótese e que os fatos observados sejam examinados sistematicamente mediante experimentação e uma teoria adequada. Com isso em mente, se faz necessário o estudo de alguns pontos utilizados na disciplina de processamento de linguagem natural de forma a obter a base necessária para uma correta exploração e aplicação das possibilidades.
A linguagem é um meio de comunicação com o qual podemos falar, ler e escrever. Por exemplo, pensamos, tomamos decisões, planejamos e muito mais em linguagem natural, no nível mais básico, em palavras. No entanto, a grande questão que nos confronta ao pensar no contexto da IA, é que podemos nos comunicar de maneira semelhante com os computadores. Em outros termos, pensamos de forma intuitiva que nós, seres humanos podemos nos comunicar com computadores em linguagem natural. É um desafio tentar desenvolver aplicativos de Processamento de Linguagem Natural (PNL), porque os computadores precisam de dados estruturados, mas a fala humana não é estruturada e muitas vezes é ambígua por natureza.
Nesse sentido, podemos dizer que o Processamento de Linguagem Natural é um subcampo da Ciência da Computação, especialmente da Inteligência Artificial (IA), que se preocupa em permitir que os computadores entendam e processem a linguagem humana1.
Tecnicamente, a principal tarefa da PNL seria programar computadores para analisar e processar grandes quantidades de dados de linguagem natural.
Esse trabalho se propõe a trazer uma introdução ao estudo do Processamento de Linguagem Natural (Natural Language Processing). Minha intenção é olhar para sua base teórica enquanto disciplina. Sendo assim vamos passar por algumas definições e conceitos antes de avançar nas questões práticas. Vamos falar sobre a estrutura de uma linguagem, compiladores, árvores sintáticas e as complexidades da linguagem natural antes do famoso mão na massa, até por que talk is cheap, show me the code.
Antes de iniciar, se faz importante informar que alguns dos termos utilizados serão apresentados em inglês e português. Para que não seja causada nenhuma estranheza ao leitor, vou priorizar os termos técnicos em inglês, e achando necessário realizo a explicação/tradução do mesmo. Para facilitar a leitura, algumas referências serão colocadas durante o texto. As demais estão todas na sessão de Referências ao final deste texto.
1.1. Justificativa
O desenvolvimento do presente artigo centra-se em algumas questões que cercam a linguística, como: Quando começou realmente a linguística? Quais teorias e seus respectivos objetos encontram-se em concorrência na linguística? E a partir do desenvolvimento de respostas para essas perguntas, o artigo será encaminhado para outras questões, como: De que forma teorias anteriores influenciaram o que se chama hoje sociolinguística? A língua muda através do tempo? Como? Por quê? O intuito é responder a esses questionamentos de modo a chegar no principal objetivo, que é perceber a forma com que uma teoria, ao desenvolver-se, apropriou-se do que era importante em outras teorias para então chegar à sociolinguística, cujo objeto de estudo é a gramática da comunidade de fala.
Ao responder às primeiras questões, o que aparecerá no debate serão as concepções iniciais de linguagem, postuladas pelos filósofos anteriores ao século XIX, como Platão e Aristóteles, quando a “linguística” (entre aspas, pois o que existia eram estudos sobre a linguagem e não uma linguística – ciência da linguagem – propriamente dita) era dividida entre as opções nocional e filológica, desenvolvidas com maior profundidade mais à frente. Depois do século XIX, entra em debate o tópico sobre fazer da linguística uma ciência e o que aparece é a opção histórica, com a linguística histórico-comparativa. Para aprofundar esses assuntos serão abordados autores que discorrem sobre o tema: Borges Neto (2004) e Faraco (2011). A partir desse breve histórico, o artigo segue o caminho das teorias e seus objetos que estão em concorrência na linguística, passando pelo estruturalismo, com Saussure, pelo gerativismo, com Chomsky, e, finalmente, pela sociolinguística, com Labov, de onde se encaminhará o estudo para a questão da mudança linguística através do tempo.
É sabido que os primeiros estudos sobre a linguagem humana são anteriores ao século XIX (século de que data o início da linguística). Segundo Borges Neto (2004), antes do século XIX, a linguística dividia-se entre as opções nocional e filológica: a opção nocional, cujos principais representantes eram Platão e Aristóteles, referia-se ao estudo da linguagem a partir da relação entre som e sentido, ignorando qualquer tipo de variação linguística; já a opção filológica, representada principalmente pelos gramáticos alexandrinos, não ignorava a variação linguística, mas a colocava como desvio, configurando-se, desse modo, possivelmente, como a primeira perspectiva normativa/prescritiva na história dos estudos da linguagem. Segundo Borges Neto (2004), esse caráter normativo-prescritivo da opção filológica é que faz surgirem os estudos do correto/incorreto.
2. Conceitos Básicos
Este tópico é de grande importância, visto que muito da problemática encontrada na linguagem natural e sua compreensão, fazem parte do domínio computacional. Sendo assim, nosso objetivo quanto pesquisadores em Processamento de Linguagem Natural também inclui a resolução desses desafios, o que nos leva a procurar uma correta compreensão de seus conceitos base.
2.1. Teoria da comunicação
Os seres humanos são considerados animais sociais e como tal, sabemos que a linguagem é nossa principal ferramenta de comunicação. Sabemos que a música é tão remota quanto o início da comunicação verbalizada, mas a principal diferença está nos papéis exercidos. Enquanto os sinais sonoros emitidos por instrumentos rudimentares foram seguindo o caminho da subjetividade, os sons cada vez mais coordenados dos seres humanos foram seguindo para se tornarem mais claros. Partimos dos grunhidos para linguagens extremamente sofisticadas.
Mesmo após tanta evolução na comunicação falada e escrita, ainda vemos que a linguagem é um assunto complexo. A linguagem é cheia de abstrações, fluída, ambígua e muitas vezes confusa. Apesar das definições gramaticais, a linguagem é um organismo vivo e se renova muito rapidamente. Diversos termos novos surgem a cada dia, e termos conhecidos recebem uma nova significância da forma já habitual.
Quando falamos em teoria da comunicação, em termos básicos temos o papel do emissor, receptor, mensagem, código, contexto e canal. Cada um desses componentes é importante para determinar uma comunicação de sucesso. Se o emissor enviar uma mensagem para um receptor usando um código que não é conhecido pelo mesmo, ou se o contexto for desconhecido pelo receptor, ou se o canal de comunicação for insuficiente, a comunicação pode ser ruidosa e falha. Se tudo isso ainda for certeiro, temos de levar em conta que a mensagem vai ser interpretada por um receptor que vai levar em consideração sua perspectiva de mundo.
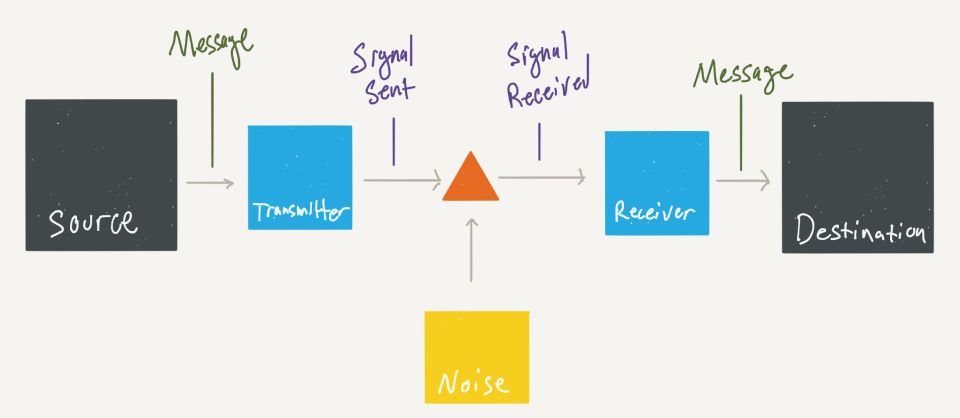
- A fonte (source) produz uma mensagem. Uma mensagem pode ser um sinal de fumaça, telégrafo, rádio e etc.
- Um transmissor (transmitter) traduz a mensagem em um sinal que possa ser enviado por um meio específico.
- O canal (medium) é apenas o meio usado para transmitir o sinal do transmissor para o receptor. Pode ser um par de fios, um cabo coaxial, banda de radiofrequência, feixe de luz e etc.
- O ruído (noise) é tudo aquilo que possa interferir no sinal.
- O receptor (receiver) normalmente executa a operação inversa da realizada pelo transmissor, reconstruindo a mensagem a partir do sinal, para que o destino possa compreender.
- O destino (destination) é a pessoa/coisa a quem a mensagem se destina.
No decorrer deste texto vamos encontrar outra estrutura que se assemelha a base da teoria da comunicação.
2.2. Linguística básica e nomenclaturas
Se tratando em linguística, temos o estudo sobre o uso e funcionamento das línguas naturais, independentemente da sua especificidade e diversidade. Nesta ciência possuímos diversas nomenclaturas. Para o objetivo proposto, precisamos conhecer os itens abaixo:
-
Língua: Podemos definir que a língua é, sobretudo, um instrumento de comunicação, e é essa a sua maior finalidade. Uma de suas riquezas e dificuldades, é que embora existam as normas gramaticais que regem um idioma, cada falante opta por uma forma de expressão que mais lhe convém, originando aquilo que chamamos de fala. A fala, embora possa ser criativa, deve ser regida por regras maiores e socialmente estabelecidas, caso contrário, cada um de nós criaria sua própria língua, o que impossibilitaria a comunicação. Na fala encontramos as variações linguísticas, visto que a língua é viva e dinâmica.
-
Idioma: É uma língua própria de um povo. Está relacionado com a existência de um Estado político, sendo utilizado para identificar uma nação em relação às demais. Existem países, como o Canadá, por exemplo, em que dois idiomas são considerados como oficiais, nesse caso, o francês e o inglês.
-
Dialeto: Por dialeto, temos o estudo da variedade de uma língua própria de uma região ou território e está relacionado com as variações linguísticas encontradas na fala de determinados grupos sociais. As variações linguísticas podem ser compreendidas a partir da análise de três diferentes fenômenos: exposição aos saberes convencionais (diferentes grupos sociais com maior ou menor acesso à educação formal utilizam a língua de maneiras diferentes); situação de uso (os falantes adequam-se linguisticamente às situações comunicacionais de acordo com o nível de formalidade) e contexto sociocultural (gírias e jargões podem dizer muito sobre grupos específicos formados por algum tipo de “simbiose” cultural).
-
Fonética: Podemos dizer que a fonética é o estudo da realidade acústica, do funcionamento articulatório e anatómico e da interpretação perceptiva dos sons de uma determinada língua natural.
-
Fonologia: É o estudo do sistema sonoro de uma língua, das regras subjacentes à combinação desses sons e do modo como esses sons exprimem distinções de significado.
-
Morfologia: A morfologia é a área da linguística que faz o estudo da formação e da estrutura interna das palavras dada uma determinada língua.
-
Sintaxe: Estudo das regras subjacentes à organização das palavras numa frase gramaticalmente bem formada. Refere-se à estrutura das frases. Regras pelas quais palavras podem ser combinadas em frases gramaticalmente aceitáveis.
-
Semântica: Estudo do significado da produção e interpretação de palavras e frases. As regras definidas na semântica servem para definir os significados de morfemas, palavras e frases, indivíduos e sentenças. Reconhecimento de palavras e sentenças ambíguas, anômalas, paráfrases, etc.
-
Pragmática: Estudo do uso da língua em contexto por oposição ao estudo do sistema da língua. Nela temos a percepção das regras que governam o uso da linguagem em contextos sociais, o que inclui o conhecimento de tipos de sentenças que são mais adequados para produzir resposta desejada, percepção da informação de fundo necessária para transmitir a mensagem visada e o entendimento dos princípios cooperativos que estão por trás das trocas na conversação.
-
Gramática: A gramática formaliza a língua, seja realizando sua descrição, seja traçando as normas para o seu uso. A linguística analisa os fatos da língua na sua situação de uso e tenta explicá-los. Ambas tratam do mesmo assunto, mas sob ângulos diferentes.
-
Semiótica: Por semiótica temos o estudo dos signos, o que abrange todos os elementos que representam algum significado e sentido para o ser humano, abarcando as linguagens verbais e não-verbais.
Claro que estou falando ainda de forma introdutória, sendo que cada tema em particular possui um campo próprio de estudo.
Nomenclatura Gramatical Brasileira (NGB)
Nossas classes gramáticais são distribuídas em 10 grupos:
- Substantivo: é a classe que nomeia os seres existentes ou que imaginamos existir;
- Artigo: é o termo que define ou indefine o substantivo;
- Adjetivo: qualifica o substantivo ou palavra substantivada;
- Numeral: expressa quantidade;
- Pronome: acompanha ou substitui um substantivo;
- Verbo: termo que expressa uma ação, um estado ou um fenômeno;
- Advérbio: modifica o verbo e exprime circunstâncias;
- Preposição: liga duas outras palavras entre si;
- Conjunção: liga orações ou termos da mesma função sintática;
- Interjeição: exprime emoções, sensações ou sentimentos repentinos.
Morfossintaxe
É a parte da gramática que define a formação, a flexão e a classificação das palavras. De acordo com (SACCONI, 1990), as palavras podem apresentar os seguintes elementos estruturais:
- Radical: parte comum das palavras da mesma família. Ex: terra, terreno;
- Afixos: juntam-se ao radical, antes (prefixos) ou depois (sufixos);
- Vogal temática: junta-se logo depois do radical;
- Tema: radical somada à vogal temática;
- Desinências: indica as flexões verbais ou nominais;
- Interfixos: intercalam-se entre o radical e o sufixo para ajudar na pronúncia.
Alguns destes conceitos serão importantes para a modelagem da redução dos termos e do sistema de conjugação e localização dos verbos.
2.3. Influências e formação da linguagem
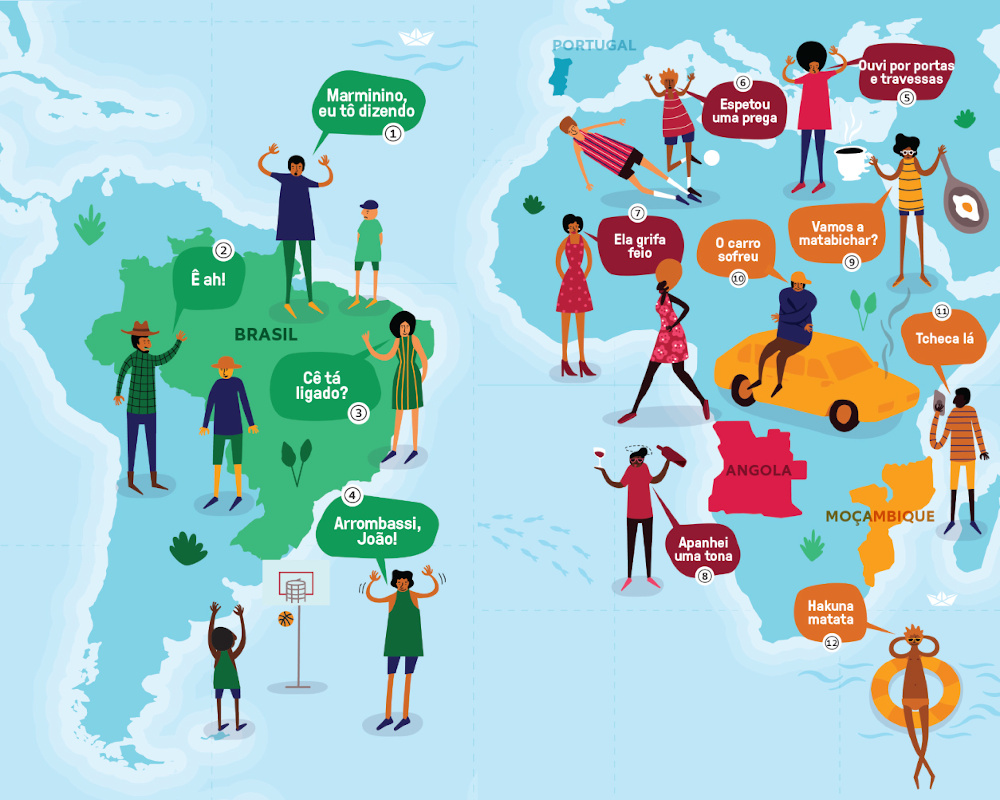
ilustração: Guilhere Lira/Mundo Estranho
Vamos fazer um exercício olhando para nossa língua natal. Quantos países têm a língua portuguesa como sua língua mater? Desses países, todos falam exatamente a mesma língua? Se iniciarmos uma comparação básica entre o que é falado no Brasil, Portugal, Moçambique e Angola, haverá muita diferença?
As grandes diferenças são as influências de línguas nativas e estrangeiras, que resultam em palavras e expressões particulares. O português brasileiro tem influência de línguas indígenas e de vários idiomas externos utilizados pelos os imigrantes, como árabes e italianos.
Em Angola, há 11 línguas e diversos dialetos que transformam o português incluindo diversas palavras ao vocabulário. Em Moçambique, o português é influenciado pelas 20 línguas locais. Apesar de ser o idioma oficial do país, em Moçambique ele é falado por apenas 40% da população. O português de Portugal possui grandes diferenças em relação ao português brasileiro. Em questões gramaticais, o português de Angola e Moçambique são mais próximos do português europeu do que o brasileiro2.
Por tudo isso, nos três países, há regionalismos que podem deixar o idioma incompreensível mesmo entre os lusófonos.
Por exemplo, aqui no Brasil nós adoramos abusar do tempo verbal gerúndio, muito pouco usado em outros países em questão. Por exemplo, usamos a frase “estou fazendo isso” no lugar de “estou a fazer isso”. Há também o gerundismo (uso desnecessário do gerúndio) como em “vamos estar averiguando”.
ilustração: Pilar Hernandez
Outro país onde a língua portuguesa sofre diversas alterações com base nas regras gramaticais das línguas locais é Moçambique. Como exemplo podemos usar o caso do verbo “nascer”, que lá é usado como na língua changana: “Meus pais nasceram minha irmã”. O mesmo vale para “Nos disseram que hoje não há aula”, que fica: “Nós fomos ditos que hoje não há aulas”.
Essas estruturas são fundamentais para um correto entendimento e aplicação dos fundamentos em processamento de linguagem natural.

Luís de Camões é considerado um dos maiores escritores de língua portuguesa e ainda, um dos maiores representantes da literatura mundial.
2.3. História
Quando como seres humanos cientes de nossa colocação no mundo nos preocupamos com o estudo da linguagem? Mais ainda, por que isso seria interessante? Este é um bônus, um ponto importante para ilustrar não só a mutabilidade como o papel da linguagem na construção e identidade de uma sociedade. A curiosidade humana sobre a linguagem é remoto e pode ser percebido por meio de vários mitos, lendas e rituais antigos.
O início dessa jornada data do século IV a.c, onde os religiosos hindus iniciaram um estudo da língua a fim de preservar os textos sagrados do Veda. Esses estudos levaram a uma rápida evolução, e mais tarde o gramático Panini (século IV a.c.) em conjunto com outros estudiosos, produziram modelos de análise dado uma minuciosa descrição da própria língua. Estes modelos só foram descobertos pelo ocidente no final do século XVIII, quando principalmente os gregos se propuseram a definir as relações entre o conceito e a palavra que o designa.
Sendo assim os gregos levaram o estudo da linguagem a outro nível. Eles questionaram coisas como: existe relação necessária entre a palavra e o seu significado? Podemos ver Platão discutindo esse ponto específico no Crátilo. Aristóteles desenvolveu estudos em outro foco, tentando proceder a uma análise precisa da estrutura linguística, chegando a elaborar uma teoria sobre distinguir as partes do discurso e a enumerar as categorias gramaticais.
Entre estudiosos latinos, temos como destaque Varrão que, na esteira dos gregos, dedicou-se à gramática, em um esforço para defini-lá como ciência e arte.
No século XVI, a religiosidade ativada pela Reforma provoca a tradução dos livros sagrados em numerosas línguas, apesar de manter-se o prestígio do latim como língua universal. Viajantes, comerciantes e diplomatas trazem de suas experiências no estrangeiro o conhecimento de línguas até então desconhecidas. Em 1502 surge o mais antigo dicionário poliglota, do italiano
Ambrosio Calepino. Introdução à linguística Volumes 1 e 2, José Luiz Fiorin
Em relação ao período moderno, podemos citar Franz Bopp como um dos principais criadores da gramática comparada. Sua obra publicada em 1816 se intitulava: Über das Conjugationssystem der Sanskritsprache in Vergleichung mit jenem der griechischen, lateinischen, persischen und germanischen Sprache (Sobre o sistema de conjugação do sânscrito em comparação com o do grego, latim, persa e germânico). Esse trabalho evidenciou diversas semelhanças entre as línguas em questão.
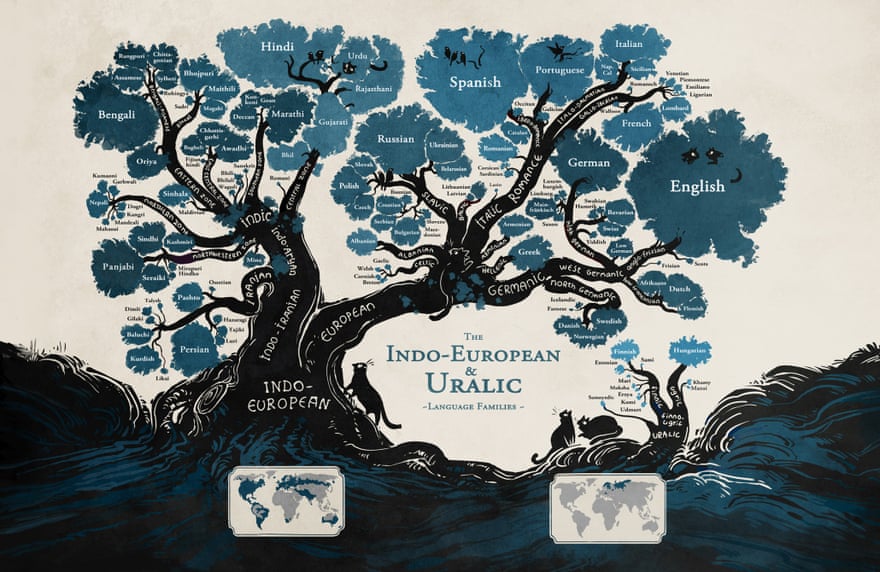
ilustração: Minna Sundberg
Ao expor as semelhanças entre essas línguas, foi notório uma relação de parentesco que originou o que hoje chamamos de família indo-européia, em que existe uma origem comum, comprovada pelo método histórico-comparativo.
Somente no início do século XX a Linguística ganhou status de estudo científico. Como estudo ela sempre foi um anexo em estudos de lógica, filosofia, retórica, história ou crítica literária. O marco foi a divulgação dos trabalhos de Ferdinand de Saussure, professor da Universidade de Genebra. Em 1916, dois alunos de Saussure, a partir de anotações de aula, publicam o Curso de Linguística geral, obra fundadora da nova ciência.
3. Linguagem Natural e sua Complexidade
A complexidade envolvida na linguagem natural passa por sua estruturação formal (gramática), até as questões mais subjetivas como interpretação. Adicione a isso o fato que temos diversas linguagens no mundo, todas com estruturas e significâncias diferentes. Se isso ainda não for suficiente, ainda temos toda a problemática envolvendo as questões de engenharia, como por exemplo, processar grandes quantidades de texto.

ref: https://www.xkcd.com/1602/
No exemplo acima, temos uma anedota em torno da palavra sesquiannual, que representa um período de 18 meses. O punch aqui é que somente uma pessoa que conhece o significa dessa palavra sabe quando o encontro vai acontecer. Este é um exemplo simples onde temos uma palavra que pertence domínio geral da língua, está nos presente nos dicionários porém não é de uso comum da população.
3.1. Compreensão semântica
O estudo da semântica alude à parte da linguagem referente ao significado das palavras e expressões que a mesma pode gerar. Neste contexto, cada palavra possui uma semântica própria, que difere da sua classificação enquanto função sintática ou morfológica3.
A comunicação humana está essencialmente ligada à capacidade de utilizar meios semióticos (como a linguagem) para transmitir as "intenções comunicativas" de um indivíduo e a capacidade de reconhecer tais intenções. DASCAL, Marcelo. Interpretação e compreensão. 2006
Contudo, de maneira geral, a semântica não é tratada de forma isolada em cada palavra, mas sim generalizada a contextos mais amplos. Sendo assim, ao considerar um diálogo, podemos identificar um significado particular em cada frase e um significado mais geral pertinente ao assunto tratado pelas pessoas que promovem o diálogo. Da mesma forma, em um texto dissertativo, mesmo considerando que cada parágrafo possa expressar um sentido particular, é somente com a junção de todas as sentenças que poderemos formar o sentido de um determinado texto.
Podemos concluir que a função base de uma linguagem é a comunicação, e esta está centrada na significância das expressões linguísticas produzidas. Como isto, o estudo da semântica ganha papel de fundamento para as implementações computacionais que envolvem compreensão e produção de linguagem. Isso dialoga diretamente com as dificuldades da envolvidas no processamento da linguagem natural, uma vez que nós utilizamos a intuição na compreensão do sentido de um determinado texto, algo que é discutível quando falamos de sua aplicação prática na computação. Como trabalhar o correto entendimento de um texto em uma máquina baseada na arquitetura de Von Neumman?

Von Neumman
Um teste simples utilizando qualquer um dos grandes tradutores online da atualidade vai nos mostrar que a tradução obtida, na maioria dos casos apresenta diversas deficiências. Mesmo que isso não comprometa a compreensão geral do contexto da tradução, se faz necessário a revisão humana para uma correta compreensão do mesmo.
O que temos de pontuar aqui, é que o processamento e tratamento computacional da linguagem natural precisa transpassar diversas barreiras, as mesmas que são típicas da comunicação humana.
Essas dificuldades são tratadas pelo cérebro de forma natural, embora já conhecemos os riscos que estão associados a comunicação humana, por mais eficiente que ela possa se dar.
3.2. Apresentando a Codificação
Se a comunicação é algo complexo mesmo para nós os seres humanos, como podemos trabalhar isso em computação?
Bom, o primeiro passo é transformar a nossa linguagem natural em algo que possa ser trabalhado por máquina. Fazemos isso transformando nosso dado textual em algum padrão de representação numérica, algo que seja processável e compreendido por uma máquina. Somente realizando esse passo é possível iniciar o processo de examinar os dados para criação de modelos matemáticos.
Esse trabalho é conhecido como codificação, e nos permite transformar um determinado sinal (imagens, sons, vídeos, textos), em algo que possas ser processado digitalmente por uma máquina. Aqui reside nosso primeiro desafio, como representar de forma eficiente dados textuais em linguagem de máquina?
Estou preparando um material específico sobre este tema, mas em resumo a técnica mais simples, e uma das primeiras a serem utilizadas é a chamada One-Hot ou 1-of-N. Esse tipo de representação, que na engenharia de software conhecemos como codificação a quente (hot encoding), simplesmente representa as palavras utilizando vetores N-dimensionais. Vejamos um exemplo baseado na fala Fernando Pessoa citada no início deste texto:
Minha pátria é minha língua.
O primeiro passo é criar uma representação baseada nas palavras únicas: [minha, pátria, é, língua]. O processo de codificação determina a geração de um vetor representativo para cada token/item/palavra do texto. Com isso chegamos ao seguinte resultado:
| minha | 1 | 0 | 0 | 0 |
|---|---|---|---|---|
| pátria | 0 | 1 | 0 | 0 |
| é | 0 | 0 | 1 | 0 |
| língua | 0 | 0 | 0 | 1 |
Essa é a representação baseada em 1 de N, e para um texto com 5 palavras, me gera 4 vetores de 4 posições. Sendo assim o número de colunas e linhas aumenta para cada palavra única. Agora imagine o quanto uma tarefa computacional pode ficar cara (processamento, memória, etc), e a media em que trabalhamos essa técnica em textos realmente grandes, isso pode muitas vezes se tornar um fator limitante. Lembre-se sempre que embora alguns desafios possam ser tecnicamente resolvidos, a relação tempo/entrega/financiamento pode ser o determinante para a continuação ou não de um projeto/pesquisa.
4. Natural Language Processing
Partindo para a área computacional, podemos conceituar NLP da seguinte maneira:
Natural Language Processing é a disciplina que consiste no desenvolvimento de modelos computacionais que utilizam informação expressa em uma determinada língua natural.
Como objetivo, podemos definir que em NLP, queremos construir mecanismos artificiais que permitem o entendimento da linguagem natural para a realização de tarefas que visam simular um comportamento humano (e.g. tradução e interpretação de textos, busca de informações em documentos, detecção de tópicos). PLN está relacionado com:
- Linguística Computacional;
- Compiladores (autômatos);
- Prova de teoremas;
- Modelos probabilísticos;
- Aprendizado de máquina;
- Interação humano-computador;
NLP se encaixa no mundo da computação como uma subárea de Inteligência Artificial, e constantemente associada a Linguística Computacional, embora sejam matérias diferentes.
Quando comparamos as aplicações desenvolvidas nessas duas áreas, é fácil entender a confusão. Geralmente compartilham as mesmas conferências, colaboram em artigos, mas tem como essência, objetivos diferentes.
| Computational Linguistics | Natural Language Processing | |
|---|---|---|
| Profissional | Linguistas | Cientistas da Computação |
| Objetivo | Uso da computação para o estudo da linguagem | Aplicações envolvendo linguagem natural |
4.1. Computational Linguistics
Como matéria segue a linha das ciências naturais como à biologia computacional, e se propõem a desenvolver métodos computacionais a fim de responder às questões científicas sobre linguística4.
As questões centrais da linguística envolvem a natureza das representações linguísticas e do conhecimento linguístico, e como o conhecimento linguístico é adquirido e implantado na produção e compreensão da linguagem. Responder a essas perguntas descreve a capacidade da linguagem humana e pode ajudar a explicar a distribuição de dados e comportamentos linguísticos que realmente observamos.
Na linguística computacional, são propostas respostas formais para essas questões. Os linguistas estão realmente perguntando o que e como os humanos estão associando. Por isso, definimos matematicamente classes de representações linguísticas e gramáticas formais (ou seja, modelos probabilísticos) que parecem adequadas para capturar a variedade de fenômenos presentes nas línguas humanas. São estudadas suas propriedades matemáticas a fim de guiar o desenvolvimento de algoritmos eficientes para o aprendizado, produção e compreensão da linguagem natural.
4.2. Natrual Language Understanding
Podemos enquadrar NLU como uma subárea em NLP. Para uma boa aplicação baseada em processamento de linguagem natural, um bom entendimento de um determinado texto é simplesmente fundamental.
Quando falamos de entendimento, estamos falando da compreensão de um dado texto e seu contexto, o que é algo realmente complexo. Parte desta complexidade se concentra em resolver alguns desafios presentes nas linguagens naturas, entre elas, destaco alguns exemplos de ambiguidades:
- Ambiguidade Lexical - Quando uma determinada palavra têm vários significados. A palavra Cobre pode ser tratar do elemento de número atômico 29 da nossa tabela periódica, ou simplesmente se tratar do verbo Cobrir.
- Ambiguidade Semântica - Quando uma determinada Sentença têm um predicado indeterminado. Na sentença “a crítica do autor”, não sabemos (sem o contexto) se o autor é o objeto ou agente da crítica.
- Ambiguidade Pedicativa - Quando uma Frase ou Palavra é mencionada anteriormente, mas no momento presente possui um outro significado.
O que dizer do sarcasmo?
“Alguns causam felicidade aonde quer que vão. Outros causam sempre que se vão” Oscar Wilde
Assim como a Visão Computacional, entendimento perfeito da linguagem é um problema conhecido como “IA-complete” o “IA-hard”. Esses por sua vez, são considerados os problemas mais complexos na computação, o que implica na resolução pro problema central da inteligência artificial: Conseguir criar um computador tão inteligente quanto um ser humano.
4.3. NLP, uma questão de engenharia
Em comparação com o a linguística computacional, podemos perceber que enquanto a CL foca na descoberta de fatos linguísticos, a NLP tem seu foco no desenvolvimento de tecnologias utilizando linguagem natural.
Em muitos casos isso é visto como uma questão de ciência versus engenharia. Não se trata de provar que as línguas X ou Y estão relacionadas historicamente. Tem mais ligação com as questões práticas e como produzir ferramentas que vão ajudar as pessoas a se comunicarem melhor (seja com o computar ou entre si), bem como trabalhar e extrair conhecimento da quantidade incomensurável de informação em linguagem natural que temos hoje.
Dado sua natureza prática, NLP é muito relacionada a questões comerciais embora tenha um papel importante em outras ciências possibilitando análises que hoje são consideradas fundamentas em áreas como política, medicina e economia.
4.4. Linguagem de programação e sua relação com NLP
Quando falamos de NLP, existe uma correlação com a Linguagem de programação que é pouco explorada. Antes de entrar no aspecto técnico, podemos citar um exemplo emblemático.

ref: Computing Machinery and Intelligence, A. M. Turing
Em meados de 1950, nos primórdios da computação como conhecemos hoje, Alan Turing escreveu o famoso artigo que mais tarde ficou famoso como o teste de Turing. Basicamente ele sugere que um computador pode ser considerado inteligente caso ele consiga por meio de uma interface conversacional, manter um diálogo com um ser humano sem que o mesmo consiga identificar que se trata de uma máquina. Sua suposição é baseada na seguinte argumentação:
Não sabemos definir precisamente o que é inteligência e, consequentemente, não podemos definir o que é inteligência artificial. Entretanto, embora não tenhamos uma definição de inteligência, podemos assumir que o ser humano é inteligente. Portanto, se uma máquina fosse capaz de se comportar de tal forma que não pudéssemos distingui-la de um ser humano, essa máquina estaria demonstrando algum tipo de inteligência que, nesse caso, só poderia ser inteligência artificial.
Sendo assim programar sistema de computador capaz de passar no Teste de Turing é uma tarefa muito difícil. Tal sistema precisaria ter pelo menos as seguintes capacidades:
- Processamento de linguagem natural: para comunicar-se com o usuário;
- Representação de conhecimento: para armazenar o que sabe ou aprende;
- Raciocínio automatizado: Para usar o conhecimento armazenado com a finalidade de responder perguntas ou tirar novas conclusões;
- Aprendizado de máquina: Para adaptar-se a novas circunstâncias, detectar e extrapolar padrões, a fim de atualizar o seu conhecimento armazenado.
É nesta época, em conjunto com a evolução da linguagem de programação que temos os primeiros programadores experimentando entradas simples de linguagem escrita para executar tarefas computacionais. Uma década após, se inicia um movimento de pesquisas sobre a utilização de textos mais próximos da linguagem natural como input para tarefas computacionais.
Grande parte do interesse nessa atividade veio da possibilidade de dar ao usuário comum, o poder de interagir com a máquina a fim de realizar tarefas e obter informações sem a necessidade de programação explícita. Isso vai se tornar popular no imaginário mundial, por meio das obras SyFy (Science Fiction) como o clássico filme de Kubrick, 2001: A Space Odyssey. Esse filme de 1968 em particular, possui diversos diálogos entre homem e máquina. O nível da conversação realizada pelo famoso computador HAL-9000 é até hoje algo só visto em filme.

ref: 2001: A Space Odyssey. 1968, Stanley Kubrick
A busca por realizar as tarefas computacionais com entradas complexas em linguagem natural se estende do início da computação moderna aos dias atuais. O famosos bots e assistentes virtuais são oriundos das interfaces conversacionais que são exploradas há décadas.
4.5. Interfaces Conversacionais, NLP, NLU, BOTs, OMG
Em relação ao processamento aplicadas Nas questões práticas, houveram diversas tentativas de no passado para utilizar linguagem natural para se trabalhar com máquinas. Partindo de Alan Turing, tivemos diversos projetos, os quais, alguns ostentam um papel de influência na história do processamento de linguagem natural.
Um caso clássico é programa ELIZA desenvolvido pelo professor Weizenbaum do MIT em 1966. Esse programa tinha entre outros, o objetivo fazer com que usuários humanos achassem que estavam conversando com outros seres humanos, e não com uma máquina. Isso te parece familiar?

Sim meus caros, estamos falando do que foi considerado a primeira interface de conversação da computação moderna, em outras palavras, o primeiro bot da era da ciência da computação. Seu objeto primordial era simular uma conversa com um terapeuta, onde o terapeuta (ELIZA) conduzia a conversa com perguntas e respostas.
Seu funcionamento era simples e baseano na extração de tokens/palavras chave dando a capacidade ao programa de decidir por um conjunto de respostas pré-programadas. Se um ser humano disser algo como “Sempre brinquei com meus irmãos na minha infância”, o software selecionaria a palavra “irmão” e faria uma pergunta como “Me conte mais sobre sua família”. Isso dava uma clara sensação ao usuário que a interação se passava com outro ser humano.
Outro exemplo clássico é o SHRDLU, que além de um nome super cool ainda integra uma entrada de linguagem natural para uma ação em processamento gráfico da máquina. Abaixo é possível ver como se dava a interface com o usuário:

O SHRDLU é considerado um software de inteligência artificial baseado em compreensão de linguagem natural. Foi desenvolvido entre os anos de 1968-1970 também no MIT por Terry Winograd. Seu funcionamento se baseava no usuário humano movendo os objetos da tela por meio de descrições abertas es linguagem natural. O esquema arquitetural utilizado no SHRDLU mostra a rápida evolução em relação ao desenvolvimento do processamento de linguagem natural na computação.
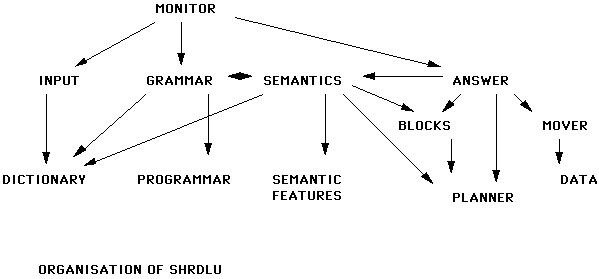
A descrição do trabalho foi explorada no artigo Procedures as a representationfor data in a computer program for Understanding Natural Language. Também foi gravado um vídeo disponibilizado pelo MIT onde é possível observar o programa em ação. Abaixo temos um exemplo da interação homem/máquina do SHRDLU.
- Person: PICK UP A BIG RED BLOCK.
- Computer: OK. (does it)
- Person: GRASP THE PYRAMID.
- Computer: I DON’T UNDERSTAND WHICH PYRAMID YOU MEAN.
- Person: FIND A BLOCK WHICH IS TALLER THAN THE ONE YOU ARE HOLDING AND PUT IT INTO THE BOX.
- Computer: BY “IT”, I ASSUME YOU MEAN THE BLOCK WHICH IS TALLER THAN THE ONE I AM HOLDING.
- Computer: OK. (does it)
Tudo isso foi de certa forma possível devido a participação dos linguistas que começaram a desenvolver diversos estudos e projetos de cunho computacional, o que nos leva ao próximo ponto.
Embora se relacione a nomenclatura do SHRDLU com a clássica disposição das letras no Linotype, segundo o autor, sua escolha foi baseada mais em relação ao famoso conto SYFY de Frederic Brown escrito em 1942 chamado ETAOIN SHRDLU. Esse conto fala sobre uma máquina Linotype que adquiri inteligência e tenta dominar o mundo (acho que já vi isso em algum lugar). A máquina ficou super inteligente por conseguir aprender tudo o que lhe era digitado. Sabendo disso, nosso herói salva a humanidade transcrevendo todos so livros sobre budismo existentes. Sendo assim o computador se convence da futilidade absoluta de todo esse esforço, alcança o Nirvana e assim a humanidade é salva. Sim, SYFY, Filosofia, Teologia e ação em 1942 ;)
Saindo da história para a engenharia, em grande parte o entendimento da estrutura interna de uma linguagem de programação traça um bom paralelo com a utilização da linguagem natural na computação. Em ambos os casos para um correto entendimento precisamos conhecer as regras que as formam. Novamente em ambos os casos, essas regras são definidas pelo que chamamos de gramática.
4.6. Gramática
Já vimos que a gramática é o conjunto de regras que indicam o uso mais correto de uma língua. No início, a gramática tinha como função apenas estabelecer regras quanto à escrita e à leitura. A palavra gramática é de origem grega vem do radical (grámma) que significa “letra”.

Noam Chomsky
Não se engane com a etimologia da palavra gramática. Como falado anteriormente, no início da década de 1950, já existiam os computadores armazenados baseados na arquitetura de Von Neumann, e que por suas limitações, dependiam de uma linguagem de montagem para a tradução do código de máquina. Já era possível na época imaginar que o próximo passo seria uma linguagem de alto nível, porém essa era uma tarefa que parecia no mínimo dispendiosa.
Este cenário mudou bem rápido. Nos anos seguintes tivemos a criação do Fortran e a primeira linguagem de alto nível para computadores. Em paralelo Noam Chomsky inicia os estudos direcionados em algoritmos para o reconhecimento da estrutura da linguagem natrual e suas complexidades gramaticais.
Qual a relação aqui? O trabalho de Chomsky sobre a sintaxe das linguagens coincidiu nitidamente com o desenvolvimento inicial das linguagens de programação, onde houve uma aplicação prática e imediata.
O foco da pesquisa de Chomsky era a linguística, entretanto logo em seu início foi possível perceber que estes estudos seriam fundamentais para o desenvolvimento das linguagens artificiais, em especial as linguagens computacionais.
Em um momento oportuno quero falar mais amplamente sobre compiladores, visto que este é um assunto que acho deveras intessante. Por hora nosso estudo da linguagem natural nos leva a analisar a estrutura de uma dada gramática. Este comportamento nos ajuda a entender como estruturar uma língua, seja ela para comunicação de um sociedade, seja ela para comunicação homem-máquina.
4.6.1. Linguagens Formais e Análise Sintática
Primeiro devo informar ao leitor que este assunto é extenso. No meu caso foi objeto de 2 semestres de estudos na faculdade. Provavelmente devo aprofundar este tema quando estiver escrevendo sobre compiladores. Por hora vamos aos conceitos principais que evidenciam o tema central.
Como vimos anteriormente, os estudos do que foi chamado Lingugens Formais trouxe uma luz para o que até então era um cenário de alta complexidade na computação. Com sua exploração das análises léxica e sintática formaram a base que pavimentou o caminho para as novas linguagens de computação. Estudar a teoria da computação fornece os conceitos base para entender a natureza geral da computação, o que envolve por definição o processamento de linguagem natural.
Por linguagem formal nos referimos a uma abstração das características gerais de uma linguagem de programação, contendo um conjunto de símbolos, regras de formação de sentenças e afins. Entre as linguagens o trabalho de Chomsky define uma ordem hierárquica que ficou intitulada como Hierarquia de Chomsky.

Essa definição de classes tenta delimitar os potenciais modelos de linguagens naturais. Cada linguagem é definida por uma determinada gramática e interpretada por um determinado reconhecedor.
| Tipo 0 | Linguagens Enumeráveis Recursivamente | Gramáticas Irrestritas | Máquinas de Turing |
|---|---|---|---|
| Tipo 1 | Linguagens Sensíveis ao Contexto | Gramáticas Sensíveis ao Contexto | Autômato Limitado Linearmente |
| Tipo 2 | Linguagens Livres de Contexto | Gramáticas Livres de Contexto | Autômatos com Pilha |
| Tipo 3 | Linguagens Regulares | Gramáticas Regulares | Autômatos Finitos |
4.6.2. Alfabeto, cadeias e linguagens
Dizemos que uma linguagem é capaz de expressar ideias, fatos e conceitos por meio de símbolos e regras de manipulação. Para este entendimento, devemos conhecer as regras e símbolos que nos permitem realizar tal tarefa, ou seja, os elementos para se montar uma gramática.
Um alfabeto é um conjunto finito de símbolos. Um símbolo de um dado alfabeto é uma entidade base, representando uma letra, número, desenho e afins. Uma cadeia de caracteres de um determinado alfabeto, é uma sequencia finita de símbolos justapostos do alfabeto em questão. O tamanho de uma determinada cadeia de caracteres é o número de símbolos que formam esta cadeia. Uma linguagem formal, ou simplesmente linguagem, é um conjunto de palavras formadas com um dado alfabeto. Também podemos dizer que
Simples não? Mas essa é a base para a formação das gramáticas utilizadas dentre otras, nas linguagens de computação.
Uma linguagem é um conjunto de sentenças, formadas pela concatenação de símbolos. Linguagens formais são linguagens artificiais (tais como lógica proposicional ou Pascal) que podem ser matematicamente definidas, de forma rigorosa. Linguagens naturais (tais como português ou inglês) não são matematicamente definidas. Embora a correspondência não seja perfeita, podemos tratar linguagens naturais como tratamos linguagens formais.
Uma gramática é uma especificação matemática da estrutura das sentenças de uma linguagem.
Tendo isso em mente podemos explorar um pouco sua estruturação. Formalmente, uma gramática é definida por:
- S: o símbolo inicial da gramática (S∈N)
- T: um conjunto de símbolos terminais, denotando palavras da linguagem (léxico).
- N: um conjunto de símbolos não-terminais, denotando componentes de sentenças.
- R: um conjunto de regras de produção, que especificam como símbolos não-terminais podem ser expandidos em símbolos não-terminais e terminais.
O professor Silvio do Lago Pereira, exemplifica a produção de uma grámatica com a seguinte árvore sintática:
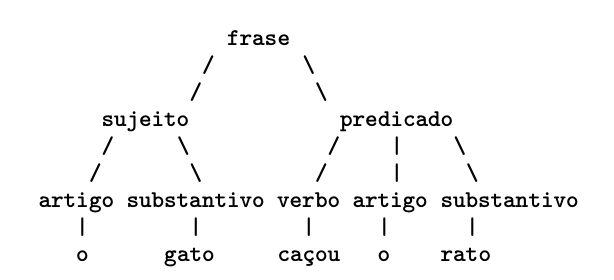
Árvore Sintática
Nessa gramática, os símbolos terminais são o, gato e rato, sendo os demais símbolos não-terminais. A regra de produção $S$ frase ⇒ sujeito predicado, estabelece que uma frase é composta de um sujeito seguido de um predicado; enquanto a regra substantivo ⇒ gato | rato estabelece que um substantivo pode ser a palavra “gato” ou “rato”. Além disso, para essa gramática, o símbolo não-terminal inicial será frase.
Nas gramáticas livres de contexto (do tipo que consideramos nesse artigo), o lado esquerdo de uma regra de produção será sempre um unico símbolo não-terminal, enquanto o lado direito pode conter símbolos terminais e não terminais.
Notem que podemos descrever as regras da produção da seguinte maneira:
S = {frase}
T = {o, gato, rato, caçou}
N = {frase, sujeito, predicado, artigo, substantivo, verbo}
R = {
frase --> sujeito, predicado;
sujeito --> artigo, substantivo;
predicado --> verbo, artigo, substantivo;
artigo --> [o];
substantivo --> [gato] | [rato];
verbo --> [caçou]
}
De acordo com esta gramática:
- Uma frase é um sujeito seguido de um predicado
- Um sujeito é um artigo seguido de um substantivo
- Um predicado é um verbo, seguido de um artigo, seguido de um substantivo
- Um artigo é o símbolo terminal
o - Um substantivo é o símbolo terminal
gatoourato - Um verbo é o símbolo terminal
caçou
Uma gramática pode ser usada tanto para reconhecimento, ou seja, para decidir se essa frase pertence a linguagem definida pela gramática; quanto para geração, ou seja, para construir uma frase pertencente a linguagem definida pela gramática. Neste caso podemos deizer que abbab e aaabbbba são cadeias sobre o alfabeto {a,b}.
Na faculdade pude utilizar o ANTLR, uma ferramenta para criação de linguagens a partir de uma gramática, gerando um analisador de linguagens formais. Com essa ferramenta é possível montar sua própria gramática e linguagem artificial de maneira simples. Recomendo para todos que queiram realizar essa tarefa ou se aprofundar no mundo das linguagens formais.
4.6.3. Sobre a lógica proposicional
Com a criação de uma gramática, estamos estabelecendo uma relação formal com a lógica proposicional. De fato, usamos uma dada lógica proposicional pra determinar a relação entre componentes utilizados em nossa produção.
A lógica em si tem um grande salto e importância que se passa de Aristóteles (384 a.C.–322 a.C.) escrevendo os primeiros grandes trabalhos de lógica, a Leibniz (1646–1716) propondo o uso de símbolos para mecanizar o processo de raciocínio dedutivo.
Como primeira e indispensável parte da Lógica Matemática temos o cálculo proposicional, sentencial ou como visto em algumas bibliografias clássicas, cálculo das sentenças. Isso por que neste contexto, uma proposição é a constituição de sentenças declarativas afirmativas (expressão de uma linguagem) da qual seja possível determinar se a mesma é verdadeira ou falsa. Em lógica e matemática, uma lógica proposicional se torna um sistema formal no qual as fórmulas representam proposições que podem ser formadas pela combinação de outras proposições usando conectores lógicos, por meio de um sistema de regras de derivação, que permita que certas fórmulas sejam estabelecidas como “teoremas” do sistema formal.
Mas por que estamos falando sobre isso?
Bom, para começar a lógica é a base do pensamento matemático. Par ser mais objetivo, este assunto ilustra como as gramáticas são pensadas (assim como quase todas as proposições computacionais), e expõem um mais ponto na complexidade do processamento de linguagem natural. Considere a lógica:
- Sócrates é homem.
- Todo homem é mortal.
- Logo, Sócrates é mortal.
Intuitivamente, deduzimos que esse argumento é válido. No entanto, usando lógica proposicional, a formalização desse argumento resulta na seguinte formação:
{p, q} |= r
Neste caso não há como mostrar que a conslusão é uma consequência lógica das premissas anterioreis (p e q). Isso acontece porque a validade desse argumento depende do significado da palavra todo, palavra essa que não pode ser expresso na lógica proposicional. De fato, para tratar argumentos desse tipo precisamos recorrer a lógica de predicados.
Não vou entrar nesse mérito, apenas quero ilustrar que do ponto de vista mais primitivo, criar lógica matemática (basicamente o que esperamos do computador) pode ser um desafio por si só, sem incluirmos as complexidades envolvidas em algo como a comunicação humana.
5. NLP, a historical Review
O artigo Natural language processing: a historical review5, sugere uma revisão da história do processamento de linguagem natural em 3 fases, agrupadas entre as décadas de 1940 a 1980, finalizando com os dias atuais, a época, 1990.
5.1. Primeira fase
(Machine Translation) - Final dos anos 1940 ao final dos anos 1960
O trabalho realizado nesta fase centrou-se principalmente na tradução automática (TA). Esta fase foi um período de entusiasmo e otimismo.
- A pesquisa sobre PNL começou no início dos anos 1950 após a investigação de Booth & Richens e o memorando de Weaver sobre tradução automática em 1949.
- 1954 foi o ano em que um experimento limitado de tradução automática do russo para o inglês foi demonstrado no experimento Georgetown-IBM.
- No mesmo ano, teve início a publicação da revista MT (Tradução Automática).
- A primeira conferência internacional sobre tradução automática (MT) foi realizada em 1952 e a segunda em 1956.
- Em 1961, o trabalho apresentado na Teddington International Conference on Machine Translation of Languages and Applied Language analysis foi o ponto alto desta fase.
5.2. Segunda fase
(AI Influenced) - Final dos anos 1960 ao final dos anos 1970
Nesta fase, o trabalho realizado relacionou-se fundamentalmente com o conhecimento de mundo e sobre o seu papel na construção e manipulação das representações de sentido. É por isso que essa fase também é chamada de fase com sabor de AI.
- No início de 1961, o trabalho começou com os problemas de endereçamento e construção de dados ou base de conhecimento. Este trabalho foi influenciado pela IA.
- No mesmo ano, também foi desenvolvido um sistema de perguntas e respostas BASEBALL. A entrada para este sistema era restrita e o processamento da linguagem envolvido era simples.
- Um sistema muito avançado foi descrito em Minsky (1968). Este sistema, quando comparado ao sistema de perguntas e respostas BASEBALL, foi reconhecido e previu a necessidade de inferência sobre a base de conhecimento na interpretação e resposta ao input da linguagem.
5.3. Terceira fase
(Grammatico-logical) - Final da década de 1970 até final da década de 1980
Esta fase pode ser descrita como a fase gramatical-lógica. Devido ao fracasso da construção prática do sistema na última fase, os pesquisadores passaram a usar a lógica para representação e raciocínio do conhecimento em IA.
- A abordagem gramatical-lógica, no final da década, nos ajudou com poderosos processadores de frases de propósito geral, como o Motor de Linguagem Central e a Teoria de Representação do Discurso do SRI, que ofereceu um meio de lidar com um discurso mais extenso.
- Nesta fase, temos alguns recursos e ferramentas práticas como analisadores, por exemplo, Alvey Natural Language Tools junto com mais sistemas operacionais e comerciais, por ex. para consulta de banco de dados.
- O trabalho sobre o léxico na década de 1980 também apontava na direção da abordagem gramatical-lógica.
5.4. Quarta Fase
Década de 1990
Podemos descrever isso como uma fase lexical e corpus. A fase tinha uma abordagem lexicalizada da gramática que apareceu no final dos anos 1980 e se tornou uma influência crescente. Houve uma revolução no processamento de linguagem natural nesta década com a introdução de algoritmos de aprendizado de máquina para processamento de linguagem.
5.5. Cenário Atual
Sobre o estado da arte vamos discutir melhor em outro post, porém uma característia do cenário atual é a capacidade de consumir serviços poderosos em diversos pilares. Particularmente, a cloud que utilizo é o Azure, que entre outros, oferece uma gama ampla de serviços de última geração para NLP como:
- Extract information
- Classify Text
- Speech (speech to text, text to speech)
- Speech Synthesis Voices
- Real time transcription
- Bach transcription
- Translator text
- Language Understanding
- QnA Maker

6. Conlusão
Existe muita confusão quando se fala em NLP. Temos diversas terminologias e conceitos que são erroneamente relacionados a essa matéria. NLP é um campo onde uma certa complexidade está associada, então um correto entendimento dos conceitos é fundamental para conseguir atingir um nível avançado de trabalho.
Fora isso a pesquisa e desenvolvimento explorando o estado da arte em NLP requer um forte conhecimento em áreas como a linguística, uma vez diversos dos problemas que hoje queremos resolver, extrapolam a engenharia para algo mais conceitual.
Parte do conhecimento necessário para performar nas atividades de NLP dependem deste conhecimento de base. Um exemplo simples seria a montagem de um bom corpus. O executor precisa conhecer a importância dos fenômenos linguisticos no contexto do problema que será explorado, caso contrário a ativdade pode não ter a representatividade e variedade necessárias para uma boa performance.
7. Referências
- Diferenças entre língua, idioma e dialeto; PEREZ, Luana Castro Alves, Brasil Escola.
- Introdução à linguística Volumes 1 e 2, José Luiz Fiorin
- A Mathematical Theory of Communication, C. E. SHANNON, harvard
- A Mind at Play: How Claude Shannon Invented the Information Age, Jimmy Soni and Rob Goodman
- Computing Machinery and Intelligence, A. M. Turing
- Introdução a semiótica, José David Campos Fernandes
- Implementação de Linguagens de Programação: Compiladores, Ana Price & Simão Toscani, editora Sagra Luzzato, 2005
- Introduction to Natural Language Understanding by Paul Renvoisé
- Terry Winograd, “Procedures as a Representation for Data in a Computer Program for Understanding Natural Language”, MIT AI Technical Report 235, February 1971
- Joseph, Sethunya & Sedimo, Kutlwano & Kaniwa, Freeson & Hlomani, Hlomani & Letsholo, Keletso. (2016). Natural Language Processing: A Review. Natural Language Processing: A Review. 6. 207-210.
- Weinreich, U. On the semantic structure of language. In: GREENBERG, J. (Ed.) Universals of Language. 2nd ed. Cambridge: MIT Press, 1963.
- Russell, S. and Norvig, P. Artificial Intelligence - a modern approach, Prentice - Hall, 1995.
- Prof. Dr. Silvio do Lago Pereira
- Russell, S. & Norvig, P. Artificial Intelligence - A Modern Approach, PrenticeHall, 1995.
-
Computational Linguistics and Natural Language Processing, Jun’ichi Tsujii, University of Tokyo ↩
-
SILVA, M.C.S; KOCH, I.V. Linguística Aplicada ao Português: Morfologia. 18ª ed. – São Paulo: Cortez, 2012. ↩
-
Interpretação e compreensão. Marcelo DASCAL ↩
-
Introduction to Computational Linguistics, Jason Eisner, Johns Hopkins University ↩
-
Jones, Karen Sparck. “Natural language processing: a historical review.” Current issues in computational linguistics: in honour of Don Walker (1994): 3-16. ↩